這裡記錄著我在研習中的學習,若有需要請點下方連結,下載上課檔案。
【DAY 1】Python與大數據資料分析(2019/10/29)
Python 簡介
Python 程式語言的特色
• 免費:開放源碼,社群支援多
• 豐富:第三方函式庫眾多
• 簡單:直譯式,容易學習
• 快速:動態型別,語法簡潔
• 有效:高階物件導向程式語言
• 可攜:跨平台、可移植、可嵌入
• 哲學:優美、明確、簡單
完整的資料分析套件
互動模式編輯器
統計科學計算
• Numpy
• Scipy
• Statsmodels
資料處理與分析
• Pandas
分散式存儲大數據處理
• PySpark
機器學習
深度學習
• TensorFlow
• Keras
• MXNet
• PyTorch
Anaconda 開發工具簡介
請至 Anaconda 官網 下載安裝應用程式。
 
Anaconda Prompt 管理模組
1 | pip list |
anaconda 升級
1 | conda update anaconda |
pip 升級
1 | python -m pip install --upgrade pip |
從命令列執行 Python 互動式Shell
C:\Users\user>python,即時看到結果,難以編修程式。
從檔案執行Python
C:\Users\user>python test.py,容易編修程式,無法即時看到結果。
編輯器介紹
【Spyder 編輯器】 Anaconda 安裝,內建應用程式。
整合開發環境(Integrated Development Environment, IDE)【PyCharm 編輯器】 官網下載
Windows User 專案開發建議使用【SublimeText 編輯器】官網下載
Windows User 專案開發建議使用【Jupyter Notebook 編輯器】
適合教學,不適合專案開發Enter(編輯模式, 綠邊)
Esc(命令模式, 藍邊)常用熱鍵:
Shift + Enter 執行再新增一列
Ctrl + Enter 執行目前列
Esc + a 在上方插入一列
Esc + b 在下方插入一列
Esc + dd 刪除一列
Esc + h 顯示快速鍵列表啟動Jupyter Notebook 編輯器
在Anaconda Prompt下打入
jupyter notebook線上雲端編輯器
Python 基本語法簡介
• 變數、註解、運算子
• 數字、字串
• 標準輸入輸出
• 列表、字典、集合、元組
• 條件判斷
• 迴圈
• 函式
• 模組
• 檔案處理
• 例外處理
變數、註解、運算子
變數(Variable)
- 變數:名稱的第一個字母必須是大小寫字母或_,不需要事先宣告變數
- 賦值:
變數名稱=資料name = 'John'; age =18; x, y = 1, 2 - 刪除變數
del 變數 - 變數資料型態
整數(int)、浮點數(float)、字串(str)、布林(bool) - 查看資料型態
type() - 資料型態轉換
int() 、float() 、str()
註解(Comment)
#單行或行內註解文字,可以在一列的開頭或中間加入"""多行註解文字,可跨越多行文字敘述…"""
“””以下是多行註解程式的說明範例
這兩行說明文字不會被執行哦!”””
X = 1 #變數X
Y=[1, 2, 3]#變數Y
#Python 變數是不需要宣告就可以使用的
運算子
- 算術運算子
+、-、*、/、% (餘數)、// (商)、**(指數) - 比較運算子
==、!=、>、>=、<、<= - 邏輯運算子
not、and、or - 複合指定運算子
+=、-=、*=、/=、%=(餘數)、//=(商)、**=(指數)
數字、字串
數字(Number)
2 + 3
#5
40 -3 * 5#25
(40 -3 * 5) / 4#6.25
(40 -3 * 5) // 4 #取商數#6
(40 -3 * 5) % 4 #取餘數#1
2 ** 3#8
a = 10; b = 2
#注意:兩個整數相除,結果是實數
a / b#5.0
type(a)#<class 'int'>
type(a / b)#<class 'float'>
c = 1.2e-12
type(c)#<class 'float'>
d = 5.5 + 6j
type(d)#<class 'complex'>
字串(String)
- 以單引號括住字串
Str1 = 'This is a string' - 以雙引號括住字串
Str2 = "This is also a string" - 以三個單引號括住做多行字串處理
Str3 = '''This is a multiple line string very loooooooooooooong text…'''
字串索引
- s = ‘Python’
- 索引值由0開始。例:s[0]
Ps[1]y - 索引值可為負號從右取值由-1開始。例:s[-1]
ns[-2]o - 索引值可用:來選定起迄點等切片範圍。例:
• s[1:3]yts[:4]Pyths[2:]thon
• s[::2]Ptos[::-1]nohtyP
字串支援的方法
• s = ‘Python’
• dir(s) #可查詢字串支援的方法
• s.upper() #將字串轉大寫
• s.lower() #將字串轉小寫
• s.split(‘t’) #根據某字元將字串切割
• len(s) #檢查字串的長度
標準輸入輸出
標準輸入input()和輸出Print()
1 | input("…") # 在螢幕上顯示字串,並等待使用者輸入字串 |
print 函式
1 | print("I'm 20 years old!") # Syntax Error: invalid syntax |
列表、字典、集合、元組
列表(List)
1 | List可以包含不同資料型態的元素,Python的List比較接近ArrayList |
列表生成式
列表生成式 廖雪峰的官方網站
套用List 於字串中
1 | list('a') # ['a'] |
List索引
• l = [1, 2, 3, 4, 5, 6]
• 索引值由0開始。例:l[0]1l[1]2
• 索引值可為負號從右取值由-1開始。例:l[-1]6l[-2]5
• 索引值可用:來選定起迄點等切片範圍。例:
• l[1:3][2, 3]l[:4][1, 2, 3, 4]
• l[2:][3, 4, 5, 6]
• l[::2][1, 3, 5]l[::-1][6, 5, 4, 3, 2, 1]
二維List
( 從命令列執行 Python 互動式Shell )
• 列表中的列表(二維)
1 | $ l = [[0, 0, 0], [0, 0, 0], [0, 0, 0]] |
1 | $ m = n =3 |
List的賦值(Assignment)
( 從命令列執行 Python 互動式Shell )
錯誤賦值
1 | $ l = [1, 2, 3, 4, 5, 6] |
正確賦值
1 | $ l = [1, 2, 3, 4, 5, 6] |
List支援的方法
( 從命令列執行 Python 互動式Shell )
1 | $ l = [1, 2, 3, 4, 5, 6] |
字典(Dictionary)
( 從命令列執行 Python 互動式Shell )
1 | $ dic = {key : value} # key 值必須唯一 |
集合(Sets)
( 從命令列執行 Python 互動式Shell )
1 | $ l = [1,1,2,3,4,2,1] |
集合類似數學中的集合,裡面的元素值不會重複
1 | $ l = [1,1,2,3,4,2,1] |
元組(Tuples)
( 從命令列執行 Python 互動式Shell )
1 | # 和List類似,但Tuple宣告後不能修改 |
條件判斷(Condition)
if…elif…else 流程控制
• https://www.python.org/dev/peps/pep-0008/#indentation
• PEP8建議使用 4個空格 縮排(Indentation)
1 | if 條件式一: |
- 範例: 
1
2
3
4
5
6
7
8
9
10
11score = int(input("請輸入成績:"))
if score >= 90:
print("A")
elif score >= 80:
print("B")
elif score >= 70:
print("C")
elif score >= 60:
print("D")
else:
print("E")
if 相關說明
• 不同數量的空格(或tab)縮排,會被視為不同的block
• 檔案的第一層(最外層)不可以有縮排
• 註解不受縮排規定限制
• 邏輯判斷式可以不用加括號”()”,但是如果有多個建議加括號以利閱讀
• 不管 if, elif, else 都需要加上 :
• x = int(input(“請輸入一個數字:”)) 101
• if x % 2 == 1: print (“odd”) #如果Statement很簡短,可以直接在:後面寫出
• else: print (“even”) odd
• num = ‘odd’ if x % 2 == 1 else ‘even’ #三元運算子 if 的寫法
• print(num) odd
迴圈(Loop)
for 迴圈
• for迴圈用於執行固定次數的動作
• 具備iteration特質的物件:list, set, dictionary, tuple, iteration
1 | for 變數 in iteration-Object: |
- 範例:
1
2
3
4
5sum=0
l=[1,2,3,4,5,6,7,8,9,10]
for i in l:
sum += i
print(sum) # 55
用range函式產生iteration物件來計數
1 | for 變數 in range(start, end, inc): |
- 範例:
1
2
3
4sum=0
for i in range(1,11):
sum += i
print(sum) # 55
break和continue
• break會強制跳離迴圈
- 範例:• continue會強制跳到迴圈起始處繼續執行
1
2
3
4for i in range(1,11):
if i==5:
break
print(i, end=',') # 1,2,3,4, - 範例:
1
2
3
4for i in range(1,11):
if i==5:
continue
print(i, end=',') # 1,2,3,4,6,7,8,9,10,
while 迴圈
• while迴圈用於執行不固定次數的動作
1 | while 條件式: |
- 範例:
1
2
3
4
5sum=i=0 # 計數器歸零
while (i<=10): # 決定執行條件
sum += i
i += 1 # 計數器+1
print(sum)
函式(Function)
自訂函式
• 將程式區塊定義成函式,可供重複呼叫使用
• 定義函式
1 | def 函式名稱 ([參數1, 參數2, …]): |
• 函式可以沒有參數(arguments),也可以有很多個參數
• 函式可以有傳回值(return value)
• 呼叫函式
1 | 函式名稱 ([參數1, 參數2, …]) |
1 | def say_hello(): # say_hello() # Hello |
內建函式
( 從命令列執行 Python 互動式Shell )
1 | $ all(): # 列表中所有元素為真 |
模組(Module)
import 模組
1 | import 模組名稱 |
- 範例:
1
2
3
4
5
6
7
8
9
10import random
random.randint(1,10) # 1
import random as r
r.randint(1,10) # 10
from random import randint
randint(1,10) # 5
from random import *
randint(1,10) # 10 # 在整數1~10之間隨機取值
randrange(1,10) # 9 # 在整數1~9區間隨機取值
random() # 0.22368014705368078 # 隨機生成0.0~1.0浮點數
datetime 日期時間模組
1 | import datetime # format()格式化日期參數: |
math數學模組
1 | import math |
- 範例:
1
2
3
4
5
6
7
8import math
math.ceil(168.8) # 169
math.floor(168.8) # 168
math.fabs(-168.8) # 168.8
math.pow(2,3) # 8.0
math.sqrt(81) # 9.0
math.log(10) # 2.302585092994046
math.pi # 3.141592653589793
檔案處理(File Processing)
os.path模組
1 | # os.path模組與檔案路徑操作相關 |
- 範例:
1
2
3
4
5
6
7
8
9import os
if os.path.isfile("file.txt"):
fid = open("file.txt", 'r')
if fid.mode == 'r' :
s = fid.read()
print(s)
fid.close()
else:
print("File not exist !")
open()函數
• open()用來開啟文件,回傳值是文件物件
• 物件= open(檔案, 模式) #記得要用 物件.close() 關檔
• with open(檔案, 模式) as 物件 #使用 with 會自動關檔
支援方法:
• read()可讀取文件內容,返回值是字串。
• readline()讀取文件指針處下一行,返回是字串。
• readlines() 讀取文件每一行成串列返回。
• write() 可將字串寫入文件。
• seek(偏移量, 位置) 移動文件讀取指針到指定位置。
• close() 關閉文件物件。
 
模式:
• r:唯讀,文件指針在檔頭,預設模式。
• r+:開啟文件可讀寫,文件指針在檔頭。
• a:附加,沒有檔案時會新增檔案,新增內容會放在檔尾。
• a+:開啟文件可讀寫,沒有檔案時會新增檔案,新增內容會放在檔尾。
• w:寫入,沒有檔案時會新增檔案,寫入時會複蓋原內容。
• w+:開啟文件可讀寫,沒有檔案時會新增檔案,寫入時會複蓋原內容。
讀取檔案
- 一行一行讀取檔案
1
2
3with open('file.txt','r') as fid:
for line in fid:
print("line: "+line.strip())
 
- 列表生成式法
1
2
3
4
5
6
7lines = [line.strip() for line in open('file.txt','r')]
lines
with open("file.txt", 'r') as fid:
lines = []
for line in fid:
lines.append(line.strip())
lines
 
- 讀取檔案中所有內容
1
2
3
4
5
6
7with open('file.txt','r') as fid:
#fid.seek(0, 0)
s=fid.read()
print("line: ", s)
with open('file.txt', 'r') as fid:
s = fid.read().splitlines()
s
寫入檔案
1 | # 將資料寫入檔案中 |
例外處理(Exception handling)
Try & Except例外處理
1 | try: |
• 程式出現錯誤時會傳回 exception,若不妥善處理程式有可能會當掉。
• 程式區塊一:用來執行並進行例外偵測。
• 程式區塊二:若有發生例外時執行的程式。
• 程式區塊三:若沒有發生例外時執行的程式。
• 程式區塊四:一定會執行的程式。
• except可設定多種例外狀況。若省略指定 即代表一發生例外狀況即執行。
• else、finally非必填。
- 範例:
1
2
3
4
5
6
7
8
9
10
11
12x = input ("Dividend: ") #100
y = input("Divisor: ") #0
try:
print(float(x) / float(y))
except ZeroDivisionError :
print("ZeroDivisionError")
except:
print("except")
else:
print("else except")
finally: # ZeroDivisionError after exception...
print("after exception...")
• 例外種類:
• IOError
• SyntaxError
• RuntimeError
• NameError
• ValueError
• ZeroDivisionError
• 其他…
範例-剪刀、石頭、布
第一版:文字輸入、文字輸出
1 | # 主程式 |
第二版:語音輸入、文字輸出
更新pip
1
$ python -m pip install --upgrade pip
安裝所需模組
1
2$ pip install SpeechRecognition
$ pip install PyAudio
1 | # 語音模組 |
第三版:語音輸入、語音輸出
- 安裝所需模組
1
2
3$ pip install gTTS
$ pip install pygame
$ pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host pypi.python.org urllib3
1 | # 語音模組 |
【DAY 2】Python與大數據資料分析(2019/11/05)
Python 網路爬蟲簡介
網路爬蟲(Web Crawler)
• 網路爬蟲是一種機器人,可以幫您自動地瀏覽網際網路並擷取目標資訊
• 自動化爬取目標網站,並按照您的需求蒐集目標資料
• 將非結構化資料轉變為結構化資料
網路爬蟲步驟
- 取得指定網域下的HTML 資料
• 使用Chrome瀏覽器,按右鍵”檢查”,查看網頁原始碼
• 透過requests 利用GET或POST取得HTML - 解析這些資料以取得目標資訊
• 透過開發者工具,觀察目標資訊的位置
• 透過BeautifulSoup 以lxml、xml、html5lib解析HTML、XML、HTML5 - 反覆爬取
pandas套件
pandas簡介
• Python for Data Analysis
• 源自於R
• 提供高效能、簡易使用的Table-Like資料格式(Data Frame)讓使用者可以快速操作及分析資料
Pandas可以處理的表格形式
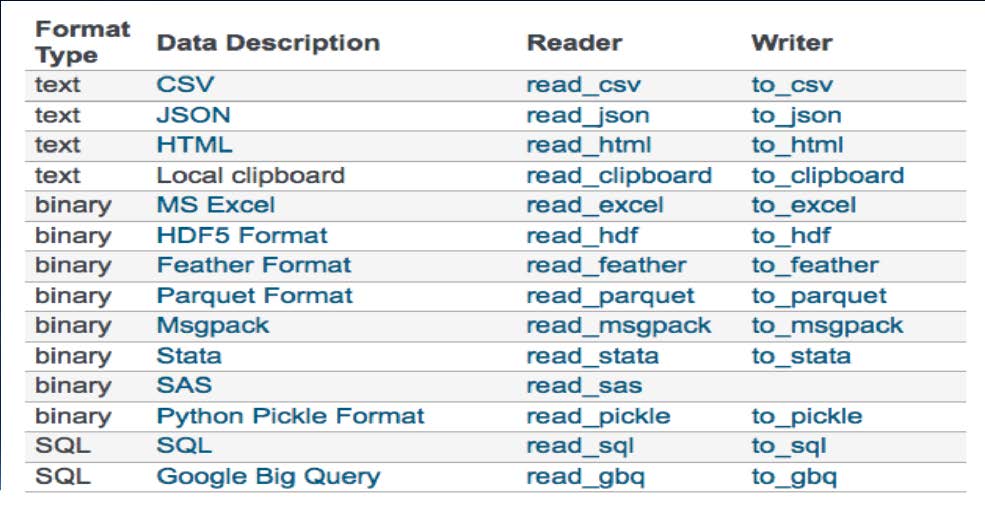
Pandas I/O讀取和寫入表格
• 使用read_xxx 來讀取表格形式之檔案,會回傳一個DataFrame ,最好使用utf-8編碼來讀取網站檔案
• 必要參數: 檔案名稱
• 選用參數encoding(有預設值): 讀取時使用文字編碼
• DataFrame = read_csv(‘檔案名稱’, encoding=‘utf-8’)
• 使用to_xxx 來儲存整理成表格形式之DataFrame到指定之檔案,最好使用utf-8來儲存檔案
• 必要參數: 檔案名稱
• 選用參數encoding(有預設值): 讀取時使用文字編碼
• 選用參數index(有預設值True): 如果不要把pandas 產生的列編號寫進檔案則要設為Flase
• DataFrame.to_csv(‘檔案名稱’, encoding=‘utf-8’, index = False)
 
 
Pandas 基本資料
• Pandas 只有兩種基本資料,一種叫做DataFrame,一種叫做Series
• 多行* 多列-> DataFrame
• 一行* 多列-> Series
• 一列* 多行-> Series
Pandas之操作
- DataFrame 大小
df.shape
- 單行篩選
df[‘行名稱’] 或df.loc[‘行名稱’]
- 多行篩選
df[ [‘行名稱1’, ‘行名稱2’, ‘行名稱3’…] ] 或df.loc[ [‘行名稱1’, ‘行名稱2’, ‘行名稱3’…] ]
- 單列篩選
df.iloc[索引值]
- 多列篩選
df.iloc[起始索引值(包括):終止索引值(不包括)] 或df.iloc[索引值1,索引值2,索引值3…]
- 多行多列篩選
先[] 再.iloc[],或者先.iloc[] 再[]
- 頭幾列篩選
df.head(索引值)
- 尾幾列篩選
df.tail(索引值)
- 單行搜尋
df[‘行名稱’].str. contains(‘特徵字串’) 作布林判斷
- 列過濾
將單行搜尋結果帶入DataFrame
df[df[‘行名稱’].str. contains(‘特徵字串’)]
- 刪除行
df.drop([‘行名稱1’, ‘行名稱2’, ‘行名稱3’…], axis = 1)
- 刪除列
df.drop([索引值1,索引值2,索引值3…], axis = 0)
範例-台灣銀行牌告匯率範例
請參閱台灣銀行牌告匯率實戰練習
beautifulsoup4 套件
- 安裝beautifulsoup4
1
pip install beautifulsoup4 # 安裝BeautifulSoup4
Beautifulsoup4 簡介
• 可以用來剖析及萃取HTML的內容
• 會自動將讀入的內容轉換成 UTF-8 編碼
• from bs4 import BeautifulSoup
• soup = BeautifulSoup(html, ‘lxml’)
認識網頁格式(HTML檔)
1 | <html> |
網頁的組成

HTML 解析
1 | • BeautifulSoup會把網頁形式的文字剖析成一顆DOM tree |
BeautifulSoup Parser
說明 https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh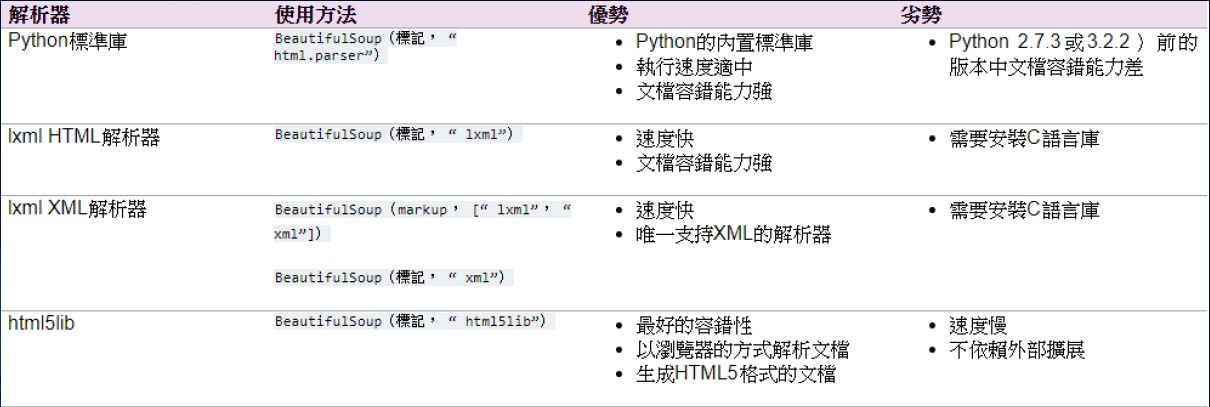
CSS(Cascading Style Sheets) Selector
1 | • 尋找某標籤的元素 |
re套件正規表達法
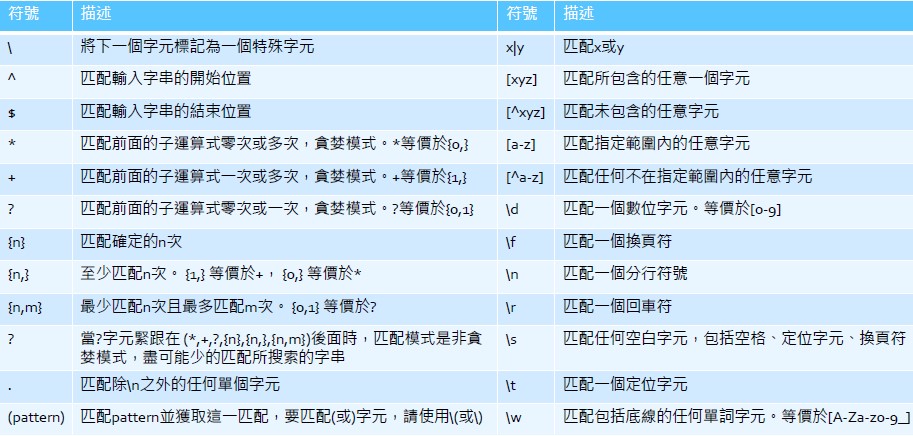
正規表達法符號之意義
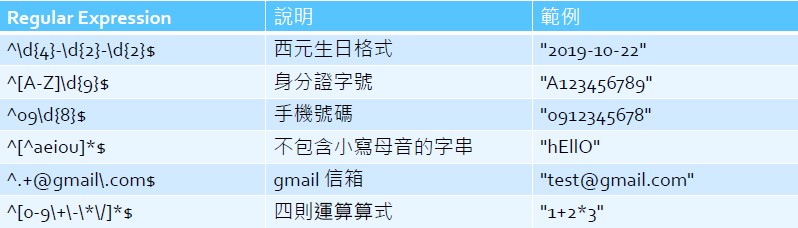
Regular Expression範例
re套件簡介
1 | # Python 內建 re 套件有Regular Expression函數 |
requests套件
- 安裝:
1
conda install requests # 安裝requests套件
GET vs. POST
• GET: 發送requests,Server 回傳資料
- 網址會隨著不同的網頁改變
- 例如:台灣銀行歷史牌告匯率查詢
https://rate.bot.com.tw/xrt/quote/l6m/JPY
https://rate.bot.com.tw/xrt/quote/l6m/USD
• POST: 發送requests 並附帶資料,Server 回傳資料
- 網址不會改變,但是網頁資料會隨著使用者不同的requests 改變
- 例如:台灣高鐵時刻表查詢
範例-台灣銀行歷史牌告匯率查詢爬取
暫不更新,將來會添加。
範例-蘋果即時新聞
1.蘋果新聞列表爬取
1 | import requests |
2.蘋果新聞內文爬取
1 | import requests |
如何使用 requests.get
1 | import requests |